
关于信息收集那些事
在安全测试中,信息收集是非常重要的一个环节,此环节的信息将影响到后续的成功几率,掌握信息的多少将决定发现漏洞机会大小(毕竟你找到的东西越多,可能出现漏洞的几率越大嘛= =)
判断有无CDN
基本上通过超级ping就可以判断了awa
有CDN–>尝试绕过
如果多地ping响应的ip不一样,说明该网站配置有CDN
绕过方法大致有:
-
DNS解析历史记录:有可能这个服务器之前没有配置CDN,查看历史DNS解析记录可以获得服务器真实IP
-
黑暗引擎搜索
-
奇怪的
www.绕过:有可能某些网站CDN配置的时候忽视了一些细节(比如说带有www.的域名配置了CDN.不带有www.的没有),部分网站可以用过ping去掉www.的域名来找出服务器真实IP, 比如说著名的学而思网校的网站= =
咳咳= = 说到这里,某些同学应该跃跃欲试了吧= =,绕过CDN的测试昨晚玩玩可以,但请不要瞎搞
- 特定文件hash值:这里放一个Python3脚本(PS:原脚本是基于python2的,我在其基础上修改了下)
# -*- coding: gb2312 -*-
print("Missing modules? Run the following commands in cmd/terminal")
print("pip install base64")
print("pip install requests")
print("pip install mmh3")
import mmh3
import requests
import base64
print("Pls input the url you want to hash favicon(Include http(s):// )")
url = input() + "favicon.ico"
r = requests.get(url)
icon = base64.b64encode(r.content)
Hash = mmh3.hash(icon)
print("The hash is:" + str(Hash))
print("Go to https://www.shodan.io/ and search with http.favicon.hash:" + str(Hash))
没有CDN–>直接上
如果多地ping响应的ip一样,说明该网站没有CDN
嘛。。。还等什么嘛= = 干就是了
判断WAF
直接上工具: wafw00f
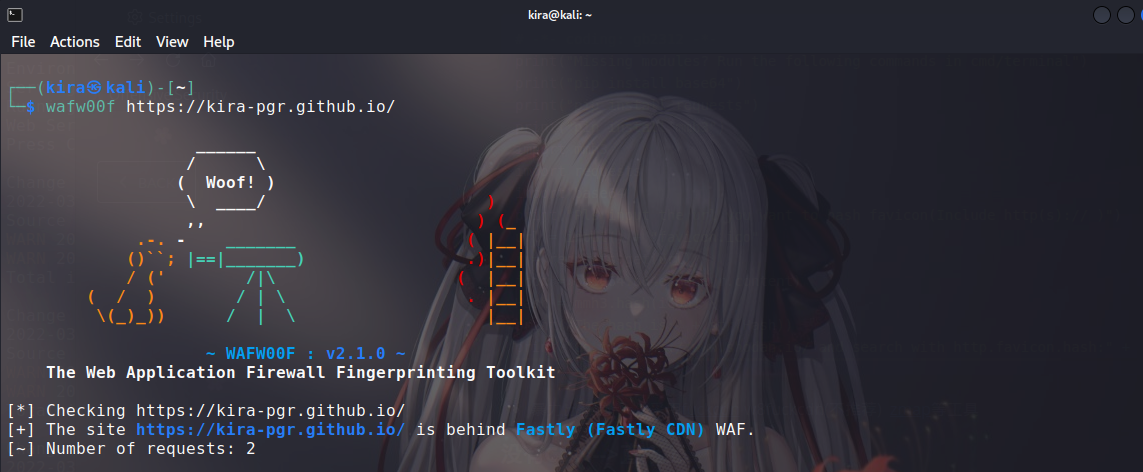
工具能帮你判断对方使用的WAF,然后你可以依据该WAF的~~特性 确信)~~来选择绕过的姿势
子域名收集
推荐工具OneForAll
子域名可能和主站在同一台服务器上,或者在同一个C段内,目标越多,发现漏洞的可能性越大
网站目录扫描
目录扫描可以让你有发现一些有趣有价值的页面
Google Hacking 语法信息收集
这种收集方式对于新手非常友好,可以用来搜寻敏感信息泄漏/弱密码/目录遍历等较容易挖掘的漏洞。
几个好用的语法:inurl: intext: intitle: site:
黑暗引擎信息收集
可以收集到网站一些和服务有关的信息,便于漏洞检测
Tip:建议通过黑暗引擎搜索的时候尽量使用语法,这样会对你信息收集更有帮助
关于操作系统的信息收集
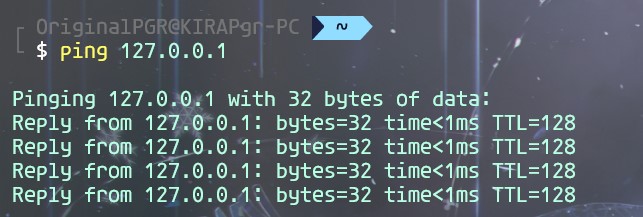
通过ttl值判断
ttl是数据包能经过路由的最大数量,每经过一次路由ttl减一。 默认情况下,不同系统ttl值的区别:
- Linux: 64
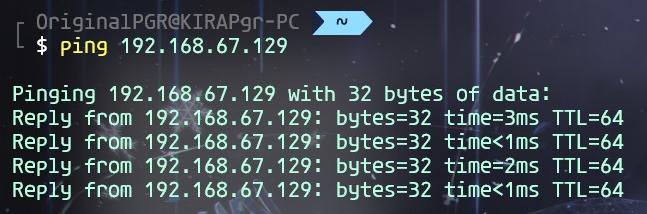
- Windows: 128
注意:TTL值是可手动修改的
通过大小写敏感判断
-
Windows:对大小写不敏感
-
Linux:对大小写敏感
这里的大小写敏感针对的是网站目录名和提交给服务器的参数名
特定的中间件只能用于特定系统
某些中间件只能用于特定的操作系统,如IIS只能用于windows,nginx只能用于Linux
关于中间件的信息收集
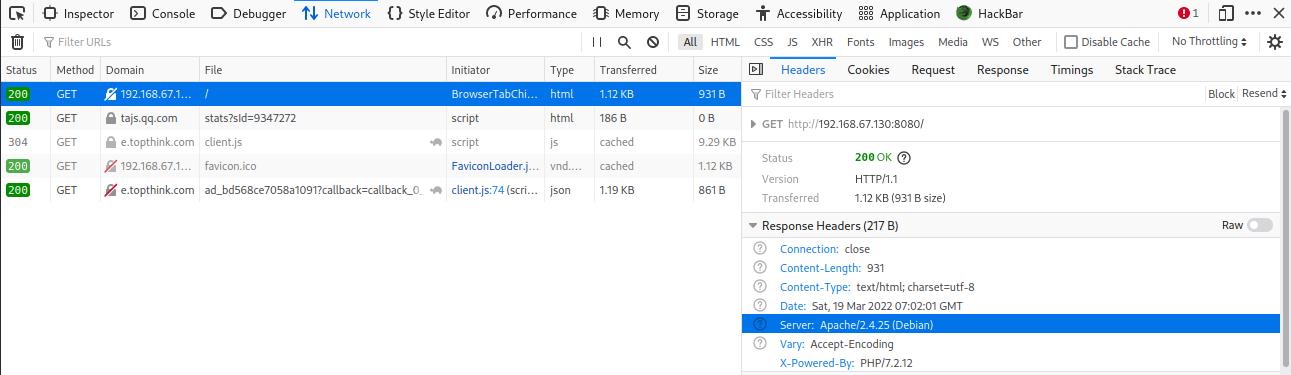
通过应答包判断
在应答包中可能会有server字段 (也就意味着可以后台手动去掉) ,其中代表的则是所有的搭建平台(中间件)类型
如何找Server字段(?
去开发者工具里网络一栏,然后刷新界面
通过报错判断
故意让网页报错,报错页面可能包含中间件一些信息
比如:
https://www.baidu.com/233333333333333333333333333
别试了,百度的报错不包含中间件信息;)
懒人必备:第三方工具
关于数据库的信息收集
黑暗引擎一把梭
见上文
依据默认端口判断
各数据库默认端口
常见搭配
某些集成化的搭建平台有着固定的网站架构搭配,如PHPStudy,在windows上常见的apache+mysql+php,linux上为nginx+mysql+php
关于后端语言的信息收集
一目了然法
对于页面直接带有相关文件后缀的,通过后缀直接判断
添加后缀法
没后缀?加着玩玩试试呗
在域名的后面手动添加index后在添加php、jsp、py、asp等常见的后端编写语言,哪个能正常显示后端就是哪个语言编写的

通过应答包判断
应答包用的好,监狱进的早就能收集到不少信息
可以通过应答包x-powered-by字段判断后端语言
Tip: 现在一些大一点的网站,安全意识较高,都会隐藏相应的字段
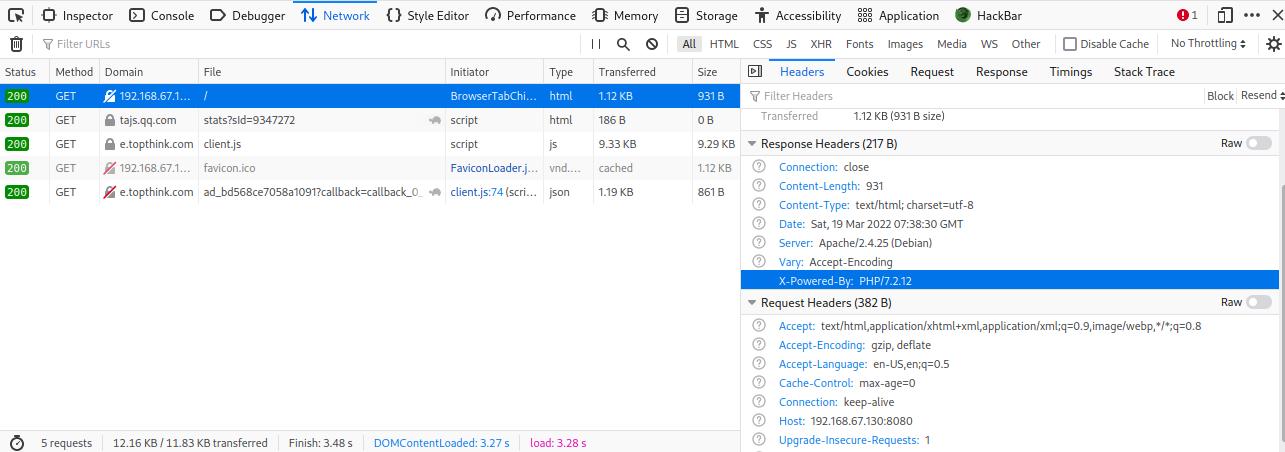
第三方平台yyds= =
关于APP的信息收集
由于部分APP是由网页封装而成,我们可以通过一些手段将对于APP的渗透测试变为Web渗透
暴力拆包找url
又到了暴力出奇迹的时候了pvp
Burp抓包APP
没有安装burp的朋友们可以看这篇文章
如果各位有安卓模拟器,可以将模拟器的代理改成Burp的代理,然后可以给模拟器安装burp的证书。
如果不想用模拟器的话可以自行参考这篇文章